Our story started since 2009 when our educational website has more than 20.000 documents and running on Plone 2.5. Its indexing/calaloging/searching was truly a nightmare. The whole site went freezed whenever a curious user performed search request or browsing the content directory. That was not going much better even when we implemented ZEO architecture on separated servers.
There are lot of things we can say regarding our implementation of Zope/Plone. Then we decided to switch to Django, along with Haystack. At the beginning, Whoosh was chosen as back-end engine.
Stuff works well at developing environment, all previous data is migrated to the new system. For some first few days, everything was fine, no more crash or timed out. But when Google done its work, indexing our storage, users came back and sometimes experienced low performance. And timed out happened when having queries with huge number of matched items found.
Lessons learned:
+ Whoosh is a pure Python library (I like it!!)
- It doesn't have separate process. The whole Django site will be affected when it is busy.
- Its performance well fits to personal project or development, not suitable to serious data site.
In the next steps, I was pretty sure that we need to:
- Select better search engine
- Optimize flow from querying to rendering (here is Django, Haystack, and Django REST Framework)
After making some benchmarks and considering between Solr, Xapian, and Elasticsearch, I decided to use ElasticSearch. Here is the comparison chart of after benchmarking:
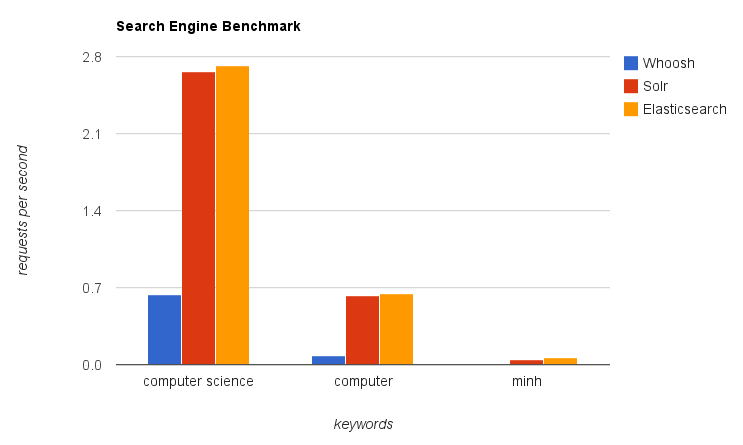
Pretty good without any further configurations. Performance is 6 to more than 10 times better than before. Here are some about Elasticsearch:
- Bases on Lucene,... it's Java!! (just like Solr)
- Consumes pretty much of resources (~500MB at normal rate)
- Very easy to deploy and integrate with Haystack
- You don't need to worry about document schema (like Solr does)
- Supports distributed model, has sharding, and real-time replication
And that is just about back-end search engine, I will write some further optimizations made in order to better improve its performance. To a good system at production, those numbers are still not acceptable.